Oracle7 Server Concepts






An Introduction to Distributed Databases
A distributed database appears to a user as a single database but is, in fact, a set of databases stored on multiple computers. The data on several computers can be simultaneously accessed and modified using a network. Each database server in the distributed database is controlled by its local DBMS, and each cooperates to maintain the consistency of the global database. Figure 21 - 1 illustrates a representative distributed database system.
The following sections outline some of the general terminology and concepts used to discuss distributed database systems.
Clients, Servers, and Nodes
A database server is the software managing a database, and a client is an application that requests information from a server. Each computer in a system is a node. A node in a distributed database system can be a client, a server, or both. For example, in Figure 21 - 1, the computer that manages the HQ database is acting as a database server when a statement is issued against its own data (for example, the second statement in each transaction issues a query against the local DEPT table), and is acting as a client when it issues a statement against remote data (for example, the first statement in each transaction is issued against the remote table EMP in the SALES database).
Oracle supports heterogeneous client/server environments where clients and servers use different character sets. The character set used by a client is defined by the value of the NLS_LANG parameter for the client session. The character set used by a server is its database character set. Data conversion is done automatically between these character sets if they are different. For more information about National Language Support features, refer to Oracle7 Server Reference.
Direct and Indirect Connections
A client can connect directly or indirectly to a database server. In Figure 21 - 1, when the client application issues the first and third statements for each transaction, the client is connected directly to the intermediate HQ database and indirectly to the SALES database that contains the remote data.
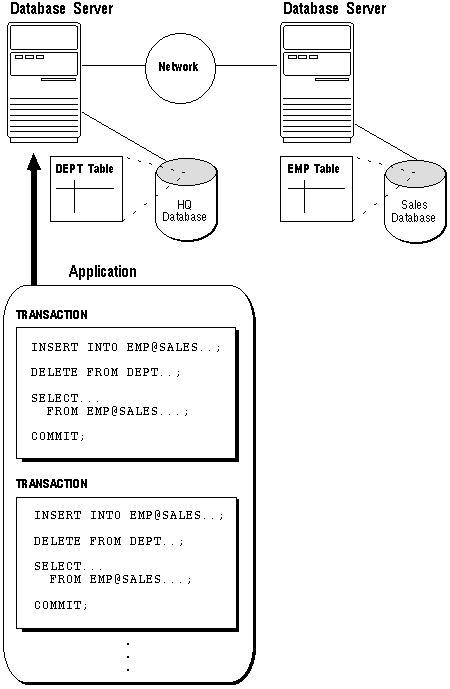
Figure 21 - 1. An Example of a Distributed DBMS Architecture
Site Autonomy
Site autonomy means that each server participating in a distributed database is administered independently (for security and backup operations) from the other databases, as though each database was a non-distributed database. Although all the databases can work together, they are distinct, separate repositories of data and are administered individually. Some of the benefits of site autonomy are as follows:
- Nodes of the system can mirror the logical organization of companies or cooperating organizations that need to maintain an "arms length" relationship.
- Local data is controlled by the local database administrator. Therefore, each database administrator's domain of responsibility is smaller and more manageable.
- Independent failures are less likely to disrupt other nodes of the distributed database. The global database is partially available as long as one database and the network are available; no single database failure need halt all global operations or be a performance bottleneck.
- Failure recovery is usually performed on an individual node basis.
- A data dictionary exists for each local database.
- Nodes can upgrade software independently.
Schema Objects and Naming in a Distributed Database
A schema object (for example, a table) is accessible from all nodes that form a distributed database. Therefore, just as a non-distributed local DBMS architecture must provide an unambiguous naming scheme to distinctly reference objects within the local database, a distributed DBMS must use a naming scheme that ensures that objects throughout the distributed database can be uniquely identified and referenced.
To resolve references to objects (a process called name resolution) within a single database, the DBMS usually forms object names using a hierarchical approach. For example, within a single database, a DBMS guarantees that each schema has a unique name, and that within a schema, each object has a unique name. Because uniqueness is enforced at each level of the hierarchical structure, an object's local name is guaranteed to be unique within the database and references to the object's local name can be easily resolved.
Distributed database management systems simply extend the hierarchical naming model by enforcing unique database names within a network. As a result, an object's global object name is guaranteed to be unique within the distributed database, and references to the object's global object name can be resolved among the nodes of the system.
For example, Figure 21 - 2 illustrates a representative hierarchical arrangement of databases throughout a network and how a global database name is formed.
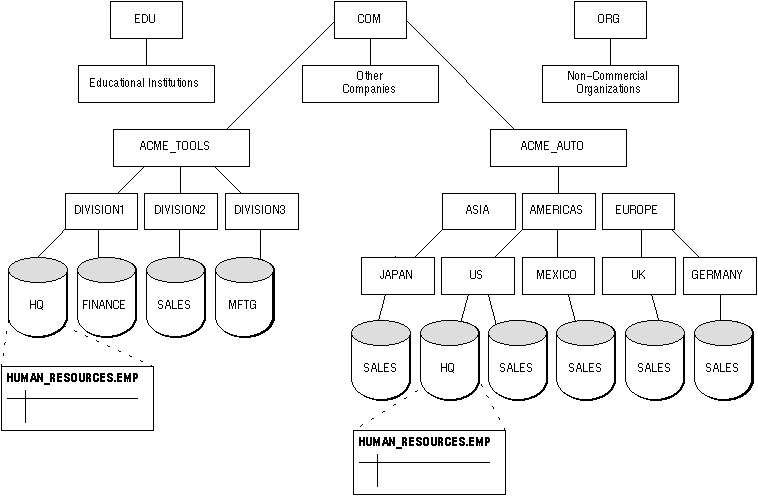
Figure 21 - 2. Network Directories and Global Database Names
Database Links
To facilitate connections between the individual databases of a distributed database, Oracle uses database links. A database link defines a "path" to a remote database.
Database links are essentially transparent to users of a distributed database, because the name of a database link is the same as the global name of the database to which the link points. For example, the following statement creates a database link in the local database. The database link named SALES.DIVISION3.ACME.COM describes a path to a remote database of the same name.
CREATE PUBLIC DATABASE LINK sales.division3.acme.com ... ;
At this point, any application or user connected to the local database can access data in the SALES database by using global object names when referencing objects in the SALES database; the SALES database link is implicitly used to facilitate the connection to the SALES database. For example, consider the following remote query that references the remote table SCOTT.EMP in the SALES database:
SELECT * FROM scott.emp@sales.division3.acme.com;
Statements and Transactions in a Distributed Database
The following sections introduce the terminology used when discussing statements and transactions in a distributed database environment.
Remote and Distributed Statements
A remote query is a query that selects information from one or more remote tables, all of which reside at the same remote node.
A remote update is an update that modifies data in one or more tables, all of which are located at the same remote node.
Note: A remote update may include a subquery that retrieves data from one or more remote nodes, but because the update is performed at only a single remote node, the statement is classified as a remote update.
A distributed query retrieves information from two or more nodes.
A distributed update modifies data on two or more nodes. A distributed update is possible using a program unit, such as a procedure or trigger, that includes two or more remote updates that access data on different nodes. Statements in the program unit are sent to the remote nodes, and the execution of the program succeeds or fails as a unit.
Remote and Distributed Transactions
A remote transaction is a transaction that contains one or more remote statements, all of which reference the same remote node. A distributed transaction is any transaction that includes one or more statements that, individually or as a group, update data on two or more distinct nodes of a distributed database. If all statements of a transaction reference only a single remote node, the transaction is remote, not distributed.
Two-Phase Commit Mechanism
A DBMS must guarantee that all statements in a transaction, distributed or non-distributed, are either committed or rolled back as a unit, so that if the transaction is designed properly, the data in the logical database can be kept consistent. The effects of a transaction should be either visible or invisible to all other transactions at all nodes; this should be true for transactions that include any type of operation, including queries, updates, or remote procedure calls.
The general mechanisms of transaction control in a non-distributed database are discussed in Chapter 12, "Transaction Management". In a distributed database, Oracle must coordinate transaction control over a network and maintain data consistency, even if a network or system failure occurs.
A two-phase commit mechanism guarantees that all database servers participating in a distributed transaction either all commit or all roll back the statements in the transaction. A two-phase commit mechanism also protects implicit DML operations performed by integrity constraints, remote procedure calls, and triggers. Two-phase commit is described in Chapter 1, "Introduction to the Oracle Server".
Transparency in a Distributed Database System
The functionality of a distributed database system must be provided in such a manner that the complexities of the distributed database are transparent to both the database users and the database administrators.
For example, a distributed database system should provide methods to hide the physical location of objects throughout the system from applications and users. Location transparency exists if a user can refer to the same table the same way, regardless of the node to which the user connects. Location transparency is beneficial for the following reasons:
- Access to remote data is simplified, because the database users do not need to know the location of objects.
- Objects can be moved with no impact on end-users or database applications.
A distributed database system should also provide query, update, and transaction transparency. For example, standard SQL commands, such as SELECT, INSERT, UPDATE, and DELETE, should allow users to access remote data without the requirement for any programming. Transaction transparency occurs when the DBMS provides the functionality described below using standard SQL COMMIT, SAVEPOINT, and ROLLBACK commands, without requiring complex programming or other special operations to provide distributed transaction control.
- The statements in a single transaction can reference any number of local or remote tables.
- The DBMS guarantees that all nodes involved in a distributed transaction take the same action: they either all commit or all roll back the transaction.
- If a network or system failure occurs during the commit of a distributed transaction, the transaction is automatically and transparently resolved globally; that is, when the network or system is restored, the nodes either all commit or all roll back the transaction.
A distributed DBMS architecture should also provide facilities to transparently replicate data among the nodes of the system. Maintaining copies of a table across the databases in a distributed database is often desired so that
- Tables that have high query and low update activity can be accessed faster by local user sessions because no network communication is necessary.
- If a database that contains a critical table experiences a prolonged failure, replicates of the table in other databases can still be accessed.
A DBMS that manages a distributed database should make table replication transparent to users working with the replicated tables.
Finally, the functional transparencies explained above are not sufficient alone. The distributed database must also perform with acceptable speed.
SQL*Net and Network Independence
When data is required from remote databases, a local database server communicates with the remote database using the network, network communications software, and Oracle's SQL*Net. Just as SQL*Net connects clients and servers that operate on different computers of a network, it also connects database servers across networks to facilitate distributed transactions. For more information about SQL*Net and its features, see "SQL*Net" ![[*]](jump.gif) .
.
Heterogeneous Distributed Database Systems
The Oracle distributed database architecture allows the mix of different versions of Oracle along with database products from other companies to create a heterogeneous distributed database system.
The Mechanics of a Heterogeneous Distributed Database
In a distributed database, any application directly connected to an Oracle database can issue a SQL statement that accesses remote data in the following ways:
- Data in another Oracle database is available, no matter what version. All Oracle databases are connected by a network and use SQL*Net to maintain communication.
Figure 21 - 3 illustrates a heterogeneous distributed database system encompassing different versions of Oracle and non-Oracle databases.
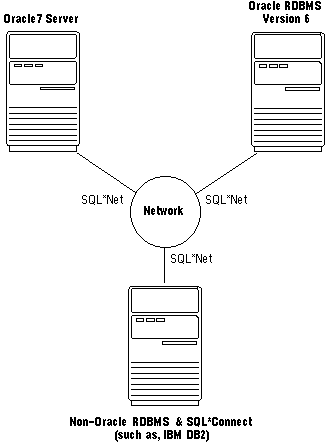
Figure 21 - 3. Heterogeneous Distributed Database Systems
When connections from an Oracle node to a remote node (Oracle or non-Oracle) initially are established, the connecting Oracle node records the capabilities of each remote system and the associated gateways. SQL statement execution proceeds, as described in the section "Statements and Transactions in a Distributed Database" .
However, in heterogeneous distributed systems, SQL statements issued from an Oracle database to a non-Oracle remote database server are limited by the capabilities of the remote database server and associated gateway. For example, if a remote or distributed query includes an Oracle extended SQL function (for example, an outer join), the function may have to be performed by the local Oracle database. Extended SQL functions in remote updates (for example, an outer join in a subquery) are not supported by all gateways; see your specific SQL*Connect documentation for more information on the capabilities of your system.